




























Data Center Redundancy 101
The world depends on data centers in all aspects of daily life. To meet all-time high levels of demand that continue to grow with no end in sight, downtime is unacceptable for most organizations.
The cost of downtime is rising and 40% of businesses report that just one hour of downtime can cost anywhere from $1 million to $5 million, not including the other associated fees. Large companies report that an interruption during peak business hours can cost almost $1 million per minute.
To mitigate the risk of such financial setbacks, data centers deploy redundant components of their critical infrastructure.
What is Data Center Redundancy?
Data center redundancy is a system used to address downtime in which extra components are included in the infrastructure design that enable operations to resume in case of an equipment failure, utility malfunction, or planned maintenance.
Why is Data Center Redundancy Important?
Data center redundancy is critical for daily operations because it provides resiliency and helps maintain uptime.
Even with some level of redundancy, unplanned downtime can occur. The damage from downtime can include:
- Lost revenue. A company that operates solely online relies on consistent uptime. If downtime occurs, it leaves customers with no way to make purchases or use services, resulting in a loss of revenue for the company.
- Brand reputation. If customers constantly experience user difficulties and downtime with your organization, they will begin to associate your brand with bad service. Making your customer’s buying process and your services as easy as possible is directly related to uptime and redundancy.
- Decreased productivity. When companies are not prepared for downtime and do not invest in redundant infrastructure, productivity ceases during an outage. Prolonged downtime can have severe consequences and can impact communication, equipment, and employee efficiency.
- Payouts. Some organizations have included language in SLA contracts that states compensation is owed in the occurrence of unplanned downtime. This is very prevalent for companies using a colocation data center and those providers agree to strict SLAs which guarantee a minimum amount of downtime to their customers.
- Lost data. During downtime, data may be unprotected and opportunities for cyberattacks that corrupt or steal data may be present.
Data center redundancy is an important measure to have because avoiding it and experiencing downtime is costly. With the average cost of one hour of downtime ranging from $140,000 to $540,000, companies should think about ensuring redundancy before it is too late. By building in redundancy, your facility can recover quicker ensuring more reliable operations. Malfunctions and failures can happen more often than you think, and it can payoff being proactive.
For instance, if a PDU fails, how will you continue operations for the equipment that it powers? Do you have redundant equipment installed for failover or will you have to wait until the issue is fixed? How much downtime can you afford without it severely affecting your organization? These are all questions to think about when asking yourself if the investment in redundancy is worth it.
What Critical Components in the Data Center Need Redundancy?
The pieces of infrastructure that are most suggested to have redundancy are:
- Power. Redundant rack PDUs, RPPs/floor PDUs, UPSs, and generators ensure that IT devices will still have power in the event one side of the power chain has a failure. Utility power can also be provided in dual feed or dual substation to safeguard against a utility failure.
- Cooling. Backup air conditioning systems, HVAC, pumps, and chillers keep the data center cool and operating safely should cooling equipment fail.
- Network. Redundant hardware like switches, routers, and firewalls can ensure operations in the event of a dramatic spike in network traffic or DDoS attack.
- Storage. Backup hard disk drives, tape drives, internal and external storage, and management software should be used to protect valuable data.
How Is Data Center Redundancy Measured?
There are different architecture designs and levels of redundancy that can be utilized based on an organization’s uptime requirements, the facility’s size, and the infrastructure’s affordability. While having a fully redundant data center can be valuable in some instances, it is extremely expensive and not efficient in others.
To measure data center redundancy, the letter N is recognized as the unit of measurement. N represents the number of instances of a specific piece of equipment that is needed for the facility to operate at 100% capacity. N itself does not offer any redundancy. To have redundancy, data center managers choose from a variety of models that add onto N.
The levels of data center redundancy are:
- N+1. N+1 is a simple redundancy design as it contains whatever number N represents for a specific component plus one extra. This extra piece of equipment is the minimal level of redundancy that can be added to the N design as it only provides one additional resource. N+1 is a well-recognized design standard, and it is a common recommendation to have one additional piece of equipment for four that are required. In 2018, Uptime Institute reported that about 51% of operator respondents have a N+1 cooling equipment design and 41% have a N+1 power equipment configuration.
- N+2. The N+1 model is helpful, but sometimes more redundancy is required. In this case, facilities might utilize a N+2 design, which deploys two extra equipment units over the baseline. The N+2 redundancy design is more cost-efficient than other complex designs.
- 2N. A 2N data center architecture design results in a fully redundant facility with a mirrored system of primary infrastructure and backup equipment. With this model, if an entire system crashes, there is an extra set of infrastructure that will be able to continue operations and support the full IT load. This can help data centers greatly reduce the risk of downtime but can be expensive and difficult to deploy.
- 2(N+1). For a data center that requires the highest level of redundancy and a fault-tolerant plan, there is a 2(N+1) architecture design. This design is a combination of the 2N and N+1 systems. It is the most expensive plan to deploy but virtually fail-proof as it can support multiple failures and still provides N+1 redundancy in the event an entire primary system fails. This model could be appropriate for companies who cannot afford the slightest of interruptions or the potential of any downtime. However, redundancy designs are not one-size-fits-all and data center managers should look at the installation, financial cost, and maintenance upkeep before choosing how much redundancy is suitable.
- 3N/2. The three-to-make-two redundancy model provides almost identical reliability as 2N and only strands about 50% capacity, making the cost closer to a N+1 system. This model is very complex as it requires three different UPS systems where each individual system could be backing up a separate system and comes with additional management challenges.
How Does Redundancy Impact Data Center Tiers?
The amount of redundancy in a data center directly relates to which data center tier the Uptime Institute grants in their certification process. There are four standardized tiers with specific criteria, specifically how much downtime is allowed per year and level of redundancy. Depending on your business needs and budget, one of the tiers will be the best fit for you.
A Tier 1 data center is typically best for smaller businesses with lower budgets. These organizations might not have tons of traffic and data storage needs and can afford a little more downtime than other tiers. In this case, no redundancy would be needed in the data center.
For a small to medium sized business, there is a slight increase in efficiency and redundancy needs making Tier 2 a good fit. A Tier 2 data center includes partial redundancy such as a N+1 model but still operates at lower costs that other higher tiers.
Larger data centers that are Tier 3 certified also need to have at least a N+1 redundancy system built in. The stakes are higher at this level and organizations must be able to conduct maintenance on equipment without shutting down or interrupting operations, making redundancy a necessity.
At the highest level of certification is Tier 4 data centers. This tier is for enterprise-class businesses and government entities that cannot afford the smallest amount of downtime at any point. For a company that requires almost 100% uptime, a fully-fault tolerant redundancy system, like a 2N or 2(N+1) design is beneficial.
Not every tier and level of redundancy is appropriate for every organization. It is important to understand how much uptime your business requires and how much you can spend on data center capacity. If you are a small-to-medium sized business, a 2N model is too complex and expensive. Investing in backup equipment that is not needed will only take up space and cost more to maintain. On the other hand, giant organizations need to make sure they are getting enough redundancy. A N+1 design will not be compatible for a company with the highest level of required uptime. Make sure to consider your organization's budget, uptime requirements, business goals, and risk tolerance when choosing how much redundancy your facility will need.
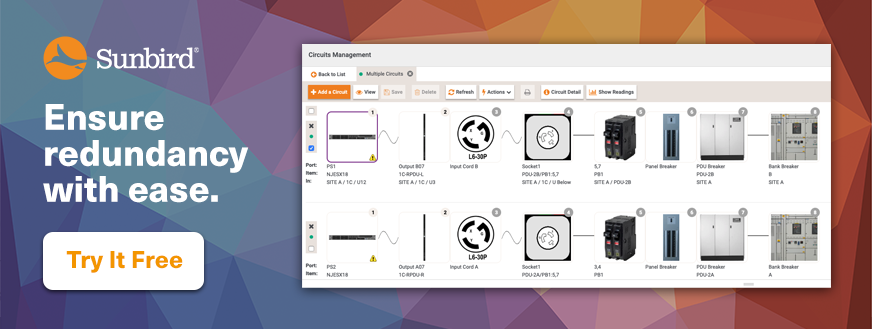
3 Ways to Ensure Redundancy with DCIM Software
Ensuring data center redundancy and maintaining uptime can be easy when you have the right tools. Data Center Infrastructure Management (DCIM) solution is a proven way to document your redundancy and improve your data center’s uptime.
Three ways DCIM software helps ensure redundancy include:
- Failover simulations. A failover is when a primary system fails, and a secondary system automatically takes over. With DCIM software, you can simulate a failover in your data center to identify which racks and equipment are at risk during a failover scenario. Then, you can proactively take steps to ensure those racks have redundant power.
- Power circuit trace diagrams. With circuit trace diagrams and 3D visualizations, you can see each node and connection in your multiple redundant power circuits from the device power supply all the way to the floor PDU.
- Health polling. It’s important to make sure that your equipment is operating properly and that you can easily access it via your network. DCIM software allows for high quality health monitoring of your intelligent PDUs and other metered devices. If a device is down, you will get an immediate alert so you can quickly react and get back to service before there is a larger issue.
Plus, by lowering the probability and severity of downtime with DCIM software, you may even find that you require less redundancy which can decrease costs.
Want to see how Sunbird’s second-generation DCIM software can help you ensure redundancy? Get your free test drive today.